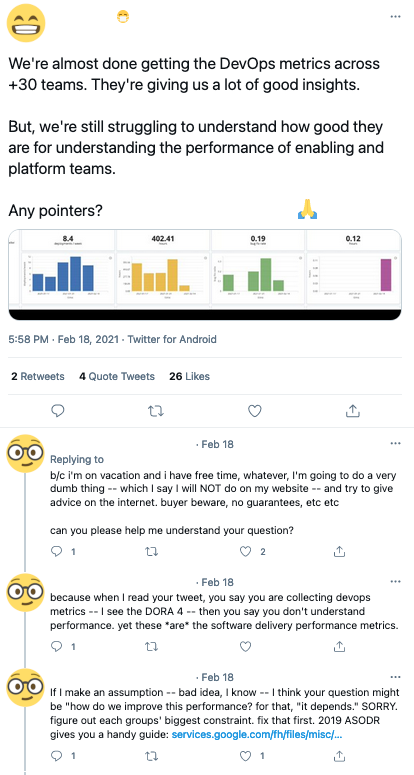
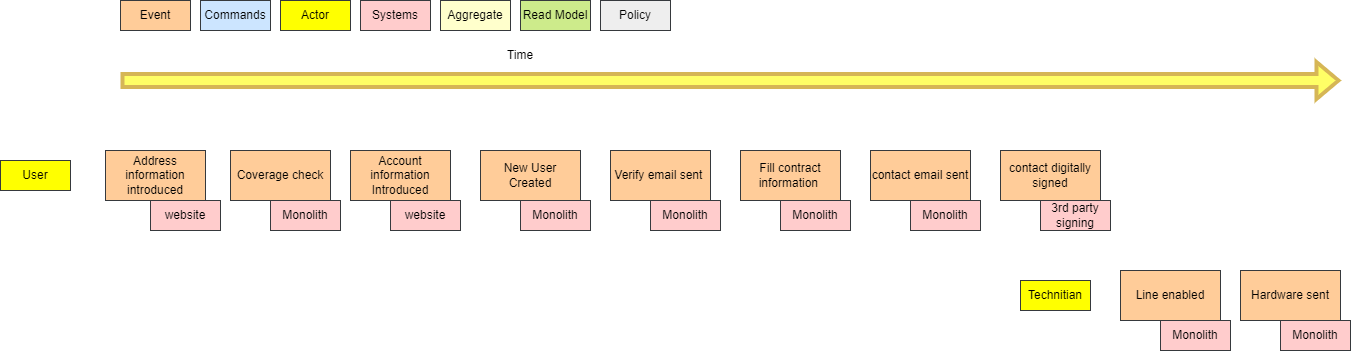
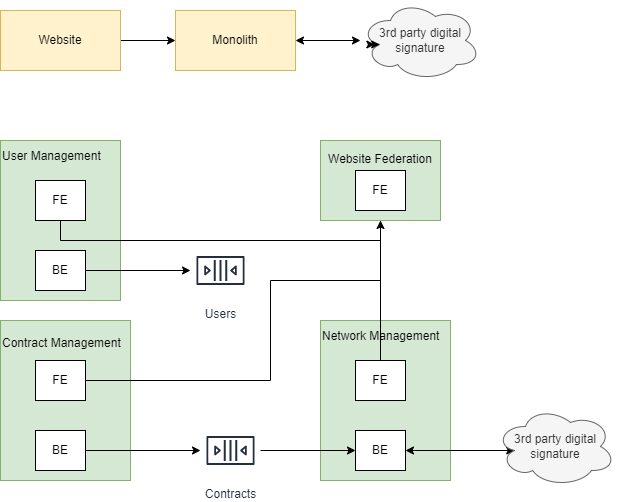
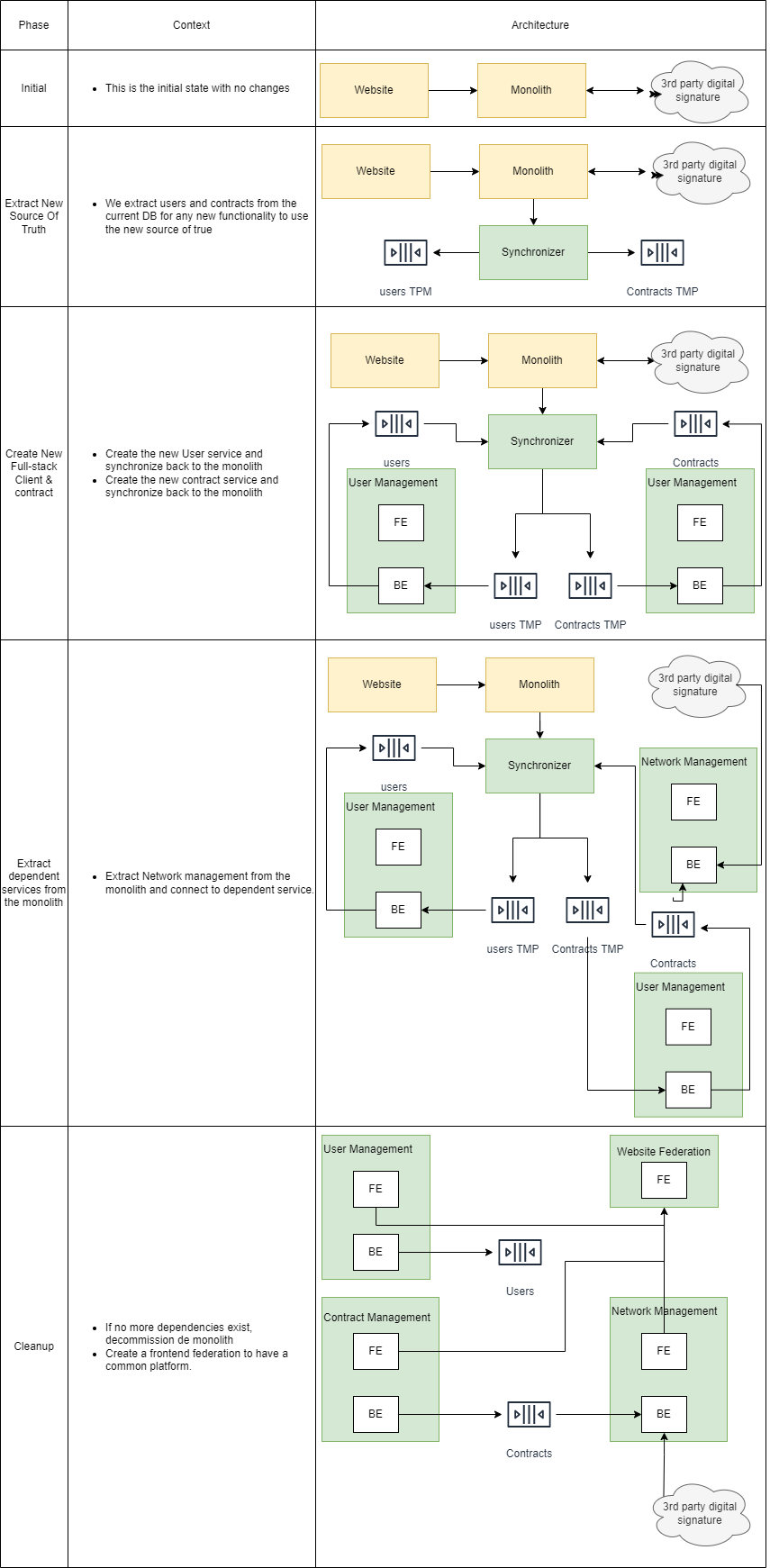
When we start our journey towards continuous integration & delivery, the first thing to take in count is the mentality. There are a few of them that will make or break our intent. Let's see the most important and also some practices.
Mentality
You build it, you run it

create a DevOps culture, not a Devs vs Ops
This mentality is the idea that the same people who develop the software re in charge to maintain it in good health by observing it.
For many years, this was not the case. Operations & development were handled by different teams. This caused a dystopian situation where each group had a different goal:
- Devs: deliver as fast as possible. By pushing code to production without observing the side effects of it.
- Ops: keep system stability.
With the 'you build it, you run it' mentality, devs focus on their service or work, while Ops becomes a product team that focus on providing the correct tooling for Developers.
This affect the next DORA 4 metrics:
- ✔️ Deployment frequency
- ✔️ Lead Time for change
- ✔️ Mean Time To Recovery
- ✔️ Change Failure Rate
Embrace Ownership in Failure Culture
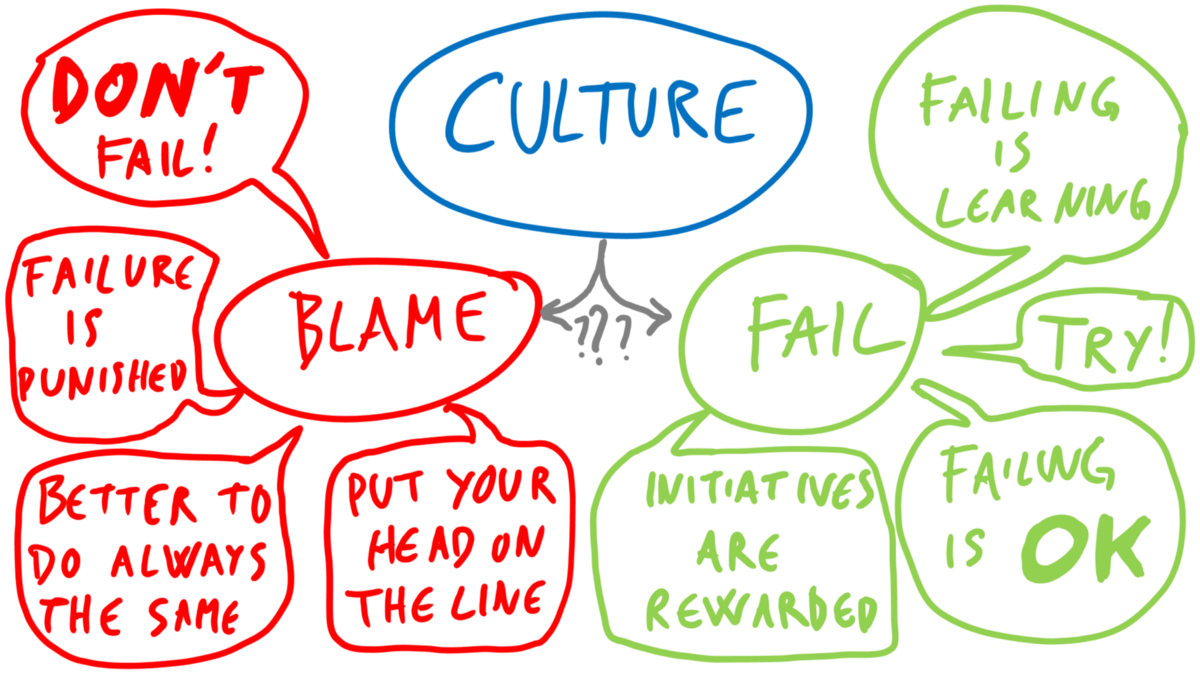
the problem is not breaking things, is the inability to recover from it
Normally, developers feel they need a safety net to feel comfortable to introduce changes to production, this tends to translate in delegating the ownership to others trough peer review or other validation step.
This lack of ownership have massive effects on the capacity to recover and the gates that code needs to go through, affecting the feedback cycle.
To improve this failure culture is necessary to promote this behavior, having no blame reduces the amount of stress people go through.
If something fails is not an issue of the individual but of the process itself.
Imagine that every commit goes to production, changes will be so small that fixing or rolling back can be done in minutes or seconds. At the same time, developers will be able to create the correct tooling to feel more comfortable with this practice.
This affect the next DORA 4 metrics:
- ✔️ Deployment frequency
- ✔️ Lead Time for change
- ✔️ Mean Time To Recovery
- ✔️ Change Failure Rate
Be a Boy Scout

Don’t continue the same path if you think something can be done better
As individuals, need to bring change to our products. If we see any new practice, tool, services… that can support the work of the team, bring it forward. Don't shy away because the team is currently doing it.
This affect the next DORA 4 metrics:
- ✔️ Deployment frequency
- ✔️ Lead Time for change
- ✔️ Mean Time To Recovery
- ✔️ Change Failure Rate
Learn & Adapt

Not everything is solved in the same way, don't follow:
If your only tool is a hammer then every problem looks like a nail
For this, learn and take your time for it. When you have a new problem, as it's possible, you don't have the correct tool in your toolbox.
This affect the next DORA 4 metrics:
- ✔️ Deployment frequency
- ✔️ Lead Time for change
- ✔️ Mean Time To Recovery
- ✔️ Change Failure Rate
Practices
Firefighter Role

The firefighter role is a rotating role inside the team. They are responsible for being the first responder to incidents and helping solve them.
At the same time, to make sure this person does not suffer from cognitive load due to context switching, this person is not involved on the normal pair rotation and development tasks.
In exchange, they focus during the week in improving the specific tooling of the project (ex. DB migration tooling).
This affect the next DORA 4 metrics:
- ✔️ Deployment frequency
- ✔️ Lead Time for change
- ✔️ Mean Time To Recovery
- ✔️ Change Failure Rate
On Call Rotation

As the development team is also in charge of running the service, some of them will require after working hour support. On call is just this, the disposition of team members to take care of their services around the clock.
This tends to sound bad, but there are ways to not make this suck. I can't express it better than Chris Ford has already done in this page.
This affect the next DORA 4 metric:
- ✔️ Mean Time To Recovery
Conclusion
These are the starting point to feel comfortable running things in production without the concern that any issue is a catastrophic thing. Failing is not an issue, the important part is to be able to recover as soon as possible from any problem that arises.