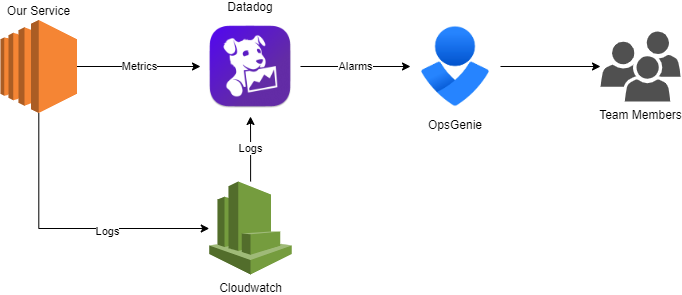
Why would I do this?
Docker-desktop is a paid product, their licensing mode is by user, and it provides value not for the software side but for their cloud offering (registry, etc). For this, if the intent of you're a company is to use containers locally to facilitate software development, the cost tends to be high.
What is podman?
Podman (short for Pod Manager) is an open-source, Linux-native tool designed to develop, manage, and run containers and container images. It offers a Docker-compatible command-line interface (CLI) that does not rely on a daemon, but directly interacts with the Image registry, container, and image storage, and container process operations.
Migration Steps
1. Clean-up Docker Desktop (Optional)
you will need to run the next bash script
#!/bin/bash
# Uninstall Script
if [ "${USER}" != "root" ]; then
echo "$0 must be run as root!"
exit 2
fi
while true; do
read -p "Remove all Docker Machine VMs? (Y/N): " yn
case $yn in
[Yy]* ) docker-machine rm -f $(docker-machine ls -q); break;;
[Nn]* ) break;;
* ) echo "Please answer yes or no."; exit 1;;
esac
done
echo "Removing Applications..."
rm -rf /Applications/Docker.app
echo "Removing docker binaries..."
rm -f /usr/local/bin/docker
rm -f /usr/local/bin/docker-machine
rm -r /usr/local/bin/docker-machine-driver*
rm -f /usr/local/bin/docker-compose
echo "Removing boot2docker.iso"
rm -rf /usr/local/share/boot2docker
echo "Forget packages"
pkgutil --forget io.docker.pkg.docker
pkgutil --forget io.docker.pkg.dockercompose
pkgutil --forget io.docker.pkg.dockermachine
pkgutil --forget io.boot2dockeriso.pkg.boot2dockeriso
echo "All Done!"
2. Install Homebrew
Homebrew is the defacto command line package manager for OSX, if you don't have it is very recommendable to have it.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
3. Install Podman
On Mac, each Podman machine is backed by a QEMU based virtual machine. Once installed, the podman command can be run directly from the Unix shell in Terminal, where it remotely communicates with the podman service running in the Machine VM.
For Mac, Podman is provided through Homebrew. Once you have set up brew, you can use the brew install command to install Podman:
brew install podman
Next, create and start your first Podman machine:
podman machine init
podman machine start
You can then verify the installation information using:
podman info
At this point, podman should have created a proxy file in /usr/local/bin/docker, if it does not exist you will have to create it with:
sudo vim /usr/local/bin/docker
add in that file the content:
#!/bin/sh
[ -e /etc/containers/nodocker ] || \
echo "Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg." >&2
exec podman "$@"
the script needs to be made executable by:
chmod +x /usr/local/bin/docker
you should now be able to run a docker as normal
docker run -it docker.io/hello-world
4. Use podman-mac-help
You should consider using podman-mac-help to migrate transparently to Podman on macOS.
- Continue using familiar Docker commands.
- Take advantage of the benefits of Podman on macOS.
- Your tools, such as Maven or Testcontainers, communicate with Podman without reconfiguration.
The podman-mac-helper tool provides a compatibility layer that allows you to use most Docker commands with Podman on macOS. The service redirects /var/run/docker to the fixed user-assigned UNIX socket location.
To enable this, you just need to run:
sudo podman-mac-helper install
5. Install Podman Desktop (Optional)
Finally, to have a better compatibility and a UI to work with as with docker desktop, you can install Podman desktopby running:
brew install podman-desktop